
My dad had a great saying for his medical students and residents.
“Eighty percent of the patients we see will get better no matter what we do, 10 percent will get worse no matter what we do. It’s the ten percent in between that we have a true opportunity to help”.
And his students probably never said this to him, but I was his daughter. I could get away with it
“Dad, how do we know which is the ten percent we can help?”
How do we identify those patients? And even if we could do that, how do we make sure we don’t screw it up and miss something?
This one concept leads us most readily into the importance of understanding the diagnostic process, and ourselves within it; the cognitive nature of medical diagnosis, even within the larger framework of decision making as a whole.
We could actually go through each chart in which a diagnosis is missed, reviewing the clinician’s process, looking at the data and deciding where the breakdown in decision making occurred. There are LOTS of problems with this.
- It’s a hard-fought [sporting event of your choice] and we already know who won and lost. Knowing the end absolutely skews data analysis. We are looking for confirmation of a diagnosis in which we are confident is correct.
- Because we know the end, small pieces of information which would have been central to making the diagnosis are more easily recognized. The narrative changes because we are telling the story with the documented conclusion in mind.
- We have oodles and oodles of time to review a chart. The clinician had maybe 5 minutes to see the patient and review the data. We are looking at the chart at our comfy desk with a cup of pour-over and fuzzy socks. The guy or girl who did the work was seeing upwards of thirty patients in clinic and was trying to get to his or her kid’s soccer game at 530.
Chances are, if a chart is being reviewed, something bad happened. While we all seek to be excellent diagnosticians, The main reason this whole topic even matters is because we are trying to avoid the catastrophic outcome.
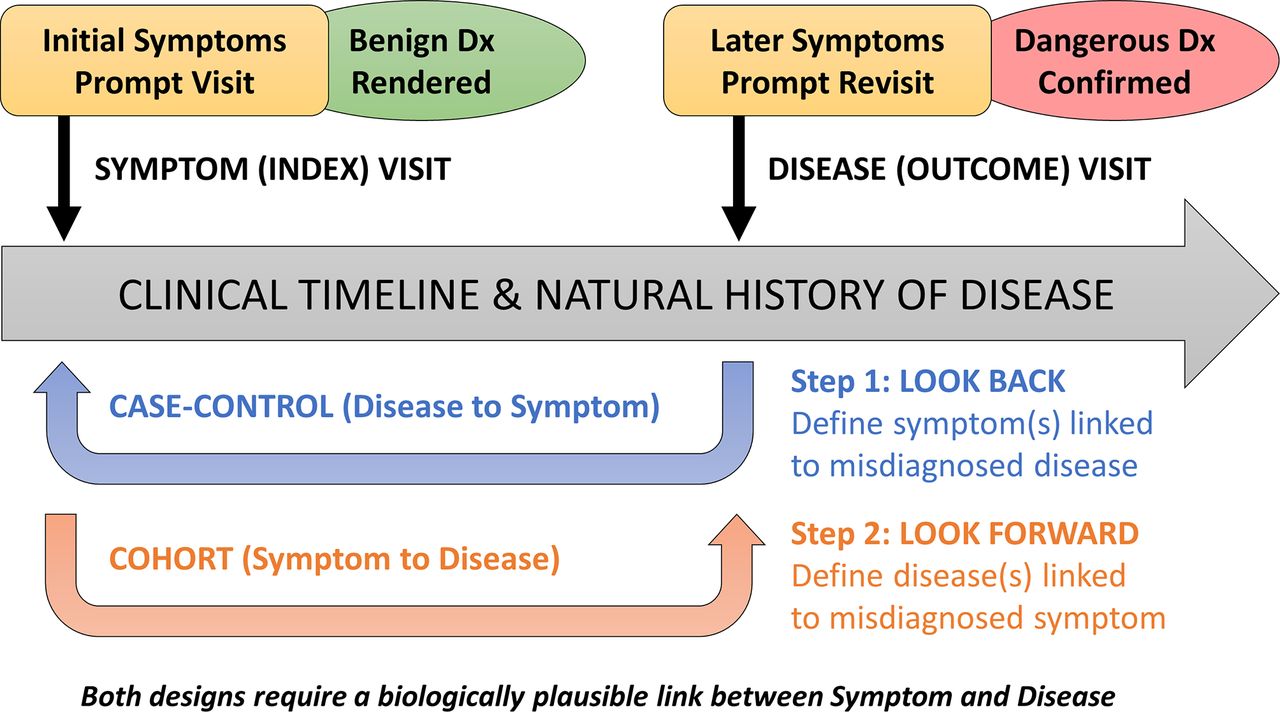
A paper published in the British Medical Journal in 2018 sought to take a broader scope of data review to identify problems with medical decision making. It discussed using Symptom- Disease Pair Analysis of Diagnostic Error (SPADE) to look at large blocks of clinical data and identify missed diagnoses (Lieberman and Newman-Toker, 2018)
Let’s say you have a 25 year old otherwise healthy female patient that comes in to an urgent care with shortness of breath. The patient is worked up, and the physician who sees her diagnoses her with bronchitis, gives her antibiotics and sends her home. Two days later, the patient presents to the Emergency Department, bottle of antibiotics in hand, with significant worsening of her symptoms. At that time, she undergoes a VQ scan which is read as high probability and she is diagnosed with a pulmonary embolus . On review of her records, we find she was started on combination oral contraceptives in the last three months, which increased her risk of thrombotic events. She is started on anticoagulants, changed to a progestin- only oral contraceptive, and is discharged home in good condition.
In our SPADE analysis, we would use the symptom-disease pair of shortness of breath- pulmonary embolus.
https://qualitysafety.bmj.com/content/qhc/27/7/557/F1.large.jpg?download=true
{kind=link}
“The framework shown here illustrates differences in structure and goals of the ‘look back’ (disease to symptoms) and ‘look forward’ (symptoms to disease) analytical pathways. These pathways can be thought of as a deliberate sequence that begins with a target disease known to cause poor patient outcomes when a diagnostic error occurs: (1) the ‘look back’ approach defines the spectrum of high-risk presenting symptoms for which the target disease is likely to be missed or misdiagnosed; (2) the ‘look forward’ approach defines the frequency of diseases missed or misdiagnosed for a given high-risk symptom presentation.” (Lieberman and Newman-Toker, 2018) .
Ideally, we can collect SPADE data on a multiplicity of symptom-diagnosis dyads and look at the number of times a diagnosis is missed by “looking back”. We can then use that data to “look forward”, based on a patient’s symptom presentation.
The authors point out that because of the ease is identifying symptoms and diagnoses in different health system databases (ICD-10 might be our friend after all:)) that collecting large amounts of data and calculating frequency of symptom to diagnosis should not only show us how often miss, it should allow us to see when we improve.
Cool. “Cool cool cool”. (Abed, “Community” 2009).
But wait. If SPADE can show us symptom-diagnosis dyads, indicating the frequency which they two may be associated, is it possible to calculate the likelihood of having a disease given a presenting symptom? And if so, are there other associated factors which may make the disease more likely in the presence of said symptom (i.e. new start oral contraceptive use and pulmonary emboli) ?
Stay tuned. We are just getting started on our journey. Thanks for reading. Peace.
“Pilot”.Community . Season 1, Episode 1, NBC, September 17,2009.
Liberman AL, Newman-Toker DE Symptom-Disease Pair Analysis of Diagnostic Error (SPADE): a conceptual framework and methodological approach for unearthing misdiagnosis-related harms using big data BMJ Quality & Safety 2018;27:557-566.